Lately i get a lot of reports throughout our apps (all apps) with:

This seems to be random, because after reloading it just works the way it should.
Any idea why this happens?
Started like 3-4 months ago.
Lately i get a lot of reports throughout our apps (all apps) with:
This seems to be random, because after reloading it just works the way it should.
Any idea why this happens?
Started like 3-4 months ago.
Hi Johan,
About 4 months ago we added the message you are seeing in case the error stack trace was empty. Before this time however, did you receive no reports at all or did you receive reports that showed an empty error stack trace?
Do you get these reports on specific jobs that could indeed have a high memory footprint, or also on simple jobs?
Well i get two mails a day more or less from end-users that press report problem.
So not sure if they are all high memory, but i do know that if they try it again it works just fine.
@khameeteman what i realised is that the error comes up the moment i press the end-point. So it isn’t really accumulating a lot of memory due to the logic present in the end-point pressed.
Is it possible, that in case this occurs you put a try and except block and if it fails, At least try it once more after 1 second?
I think that should solve 90% of the cases.
Could you give me a bit more info so we may be able to figure things out from the app logs?
Hi Kevin,
As an example:
But all Error stack traces are the same.
In this case I was thinking, maybe I didn’t close the Temporary file the correct way:
def get_buffer_as_path(buffer: BytesIO, name: str | None = None, suffix: str | None = None) -> Path:
"""Converts the filename and buffer to a Path object."""
# Assuming you have a BytesIO object
bytes_io = BytesIO(buffer.getvalue())
# Create a temporary file and write the BytesIO contents to it
with tempfile.NamedTemporaryFile(delete=False, suffix=suffix if suffix else
"", prefix=name if name else "") as temp_file:
temp_file.write(bytes_io.getvalue())
temp_file_path = temp_file.name
# Create a Path object for the temporary file
return Path(temp_file_path)
But i don’t think it should cause the problem.
We will check the logs to see if we can spot some issues, will get back to you.
@Leonard_Bonnet seems like the similar issue we told you we were experiencing.
Same here, we do not know if it is still occuring often since end user might have now taken the habit to refresh the web page. Usually, it solve the issue.
Hi Johan we have looked into this specific case, but indeed see increased memory. In the logs we see an out of memory for this job twice in a row, followed by a successful job. Could you verify that all inputs between the failing and successful jobs are identical?
In the first post you mentioned “reloading”, do you mean the user refreshes the browser? And in that case do the inputs stay exactly the same?
@Johan_Tuls @kdurando If you can, could you provide more combinations of app+timestamp of failures that indeed seem random.
A completely different app, with the first view only being showing hte soil profile:
It crashes due to the same error.
Reloading or trying again solves the problem.
Maybe it is because we have a big amount of packages (our own packages, geolib etc.) which are used. But the logic itself is really simple.
Same issue, in this case memory can’t really be a problem. The app is super simple.
Two things I was thinking:
Hopefully this gives additional information
Edit: I checked this error locally and it was the following error:
TypeError: unsupported operand type(s) for /: 'NoneType' and 'int'
So basicaly an error somewhere in the code. (Which we didn’t catch yet), however the traceback seems to be incorrect.
Thanks for the additional reports, we will inspect the logs for these cases. In the meantime, feel free to report any new case
@PanjiBrotoisworo I think your newest app might be experiencing the same issue. Feel free to report your case here in more detail.
Hi,
@mslootweg In our case we are trying to use PyVista for interactive 3D models using WebView. We did not observe any memory spike during development but encountered this issue when we were trying to export the data to HTML or gltf format.
It worked when the specifications of workspace was upgraded to 2 GB.
EDIT: Actually they changed it to 2 GB. Not 1 GB.
I have similar issue here, but now the odd thing:
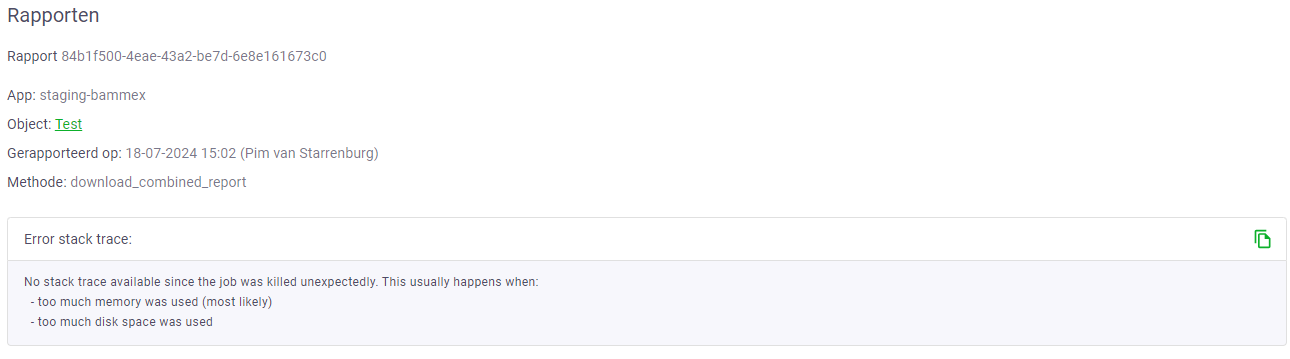
No stack trace available since the job was killed unexpectedly. This usually happens when:
- too much memory was used (most likely)
- too much disk space was used```Another usecase:
SetParamsbutton which uses the rest api to get meta data:
Another use case:
Empty table, so input validation on our side, shoudl return a stack trace.
Many more, but if they differ i will share them.
Hello everyone,
With my app:
Any ideas ?
Hi @LM_Vin do you get this error message consistently or random (with the same inputs) as Johan describes above?
Hi all,
Thanks to your reports we have been able to find the problem.
While we implemented the feature to perform job computations through our API, a bug was introduced in the way the error stack trace is stored. This results in all apps that are published from July onward showing this incorrect stack trace for every reported problem.
We are aiming to fix this in the beginning of next week.
That would be great, we get even now in the vacation period, about 2-5 problems reported a day >.<