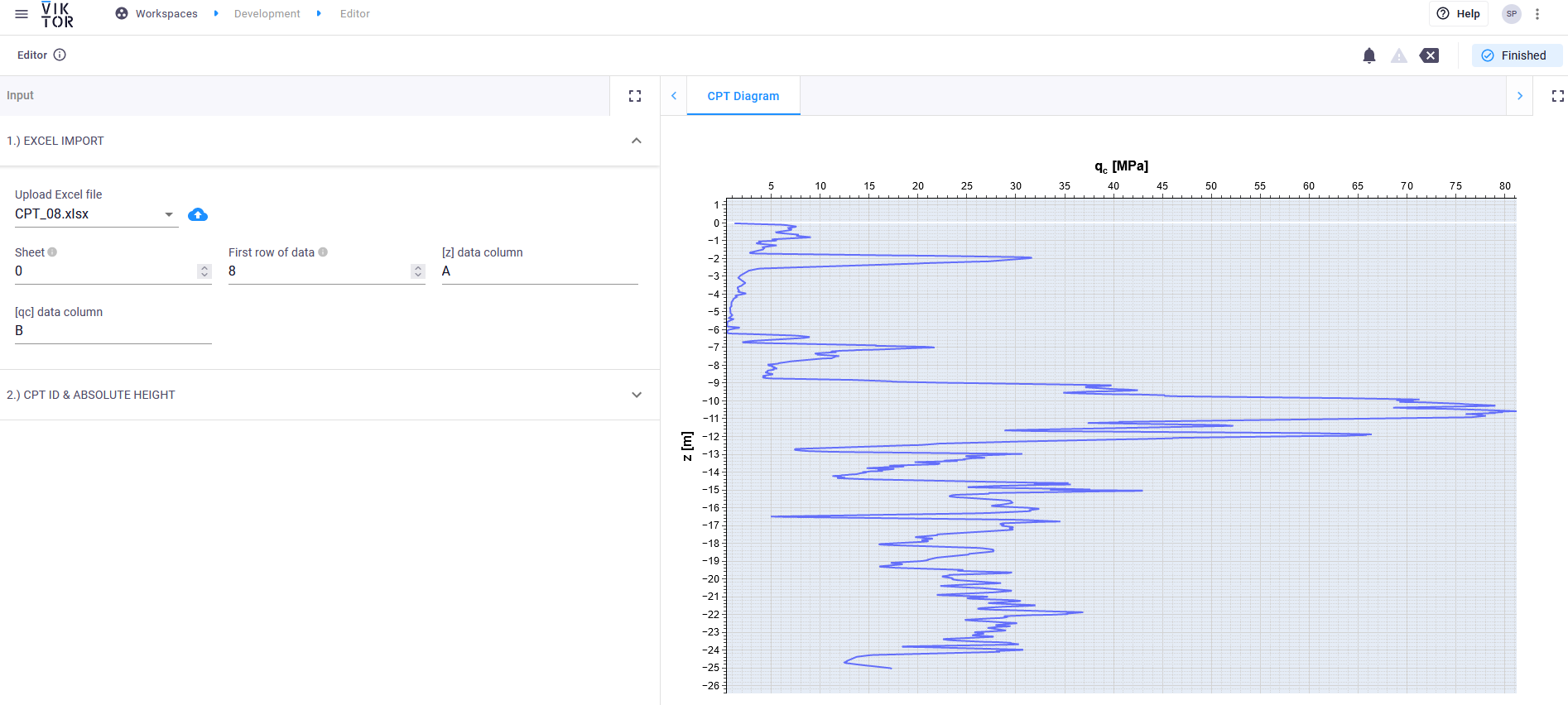
Hi All!
I am starting out with Viktor. My question is:
How exactly do you convert an uploaded Excel file to a Pandas DataFrame, which then can be used to visualize the data?
First step is to upload the Excel file with FileField, that part is easy.
Where do I have to define the custom method which contains the pd.read_excel() function?
Inside the ViktorController class? At the beginning of the code, below the import rows, before the Parametrization class?
I would also like to be able to choose the following for the import (because usually we don’t receive the data in the same formatting):
- sheet number (default: 0, so the first sheet of the file) - IntegerField?
- column (e.g. ‘A’) - TextField?
- start row of the data (‘startrow-1’ in the pd.read_excel() function) - IntegerField?
My base code looks like this in Python (not in function format):
df_z = pd.read_excel(filename,
sheet_name=sheet,
names=['z'],
usecols=col_z_data,
skiprows=(data_start_row-1))
My problem is with the ‘filename’ argument, because it does not work if I directly give the “params.upload_file” variable as an argument to the function.
I tried to replicate the solution given in this topic, but it does not seem to work. VSCode raises a problem that BytesIO is not defined. Is it a separate module which have to be imported at the beginning? If so, do I have to put it in the requirements?