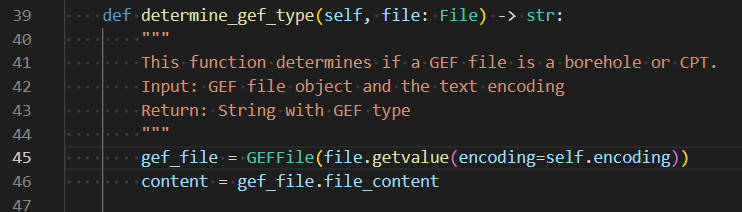
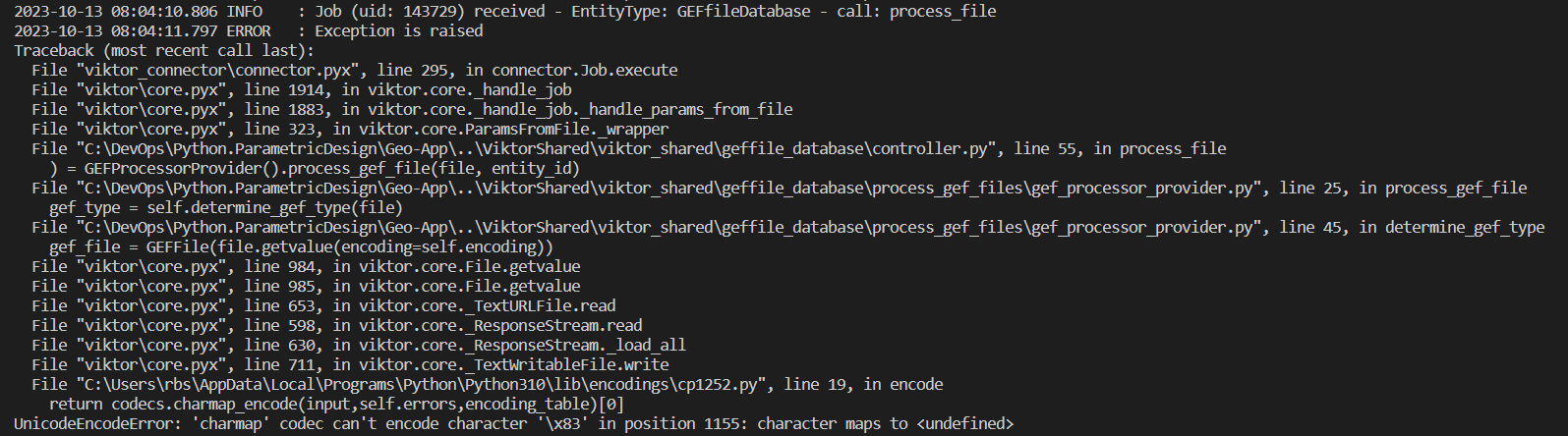
After removing the out of place characters in line 35 I was able to successfully upload the .gef file. My question is if it is possible to handle these errors on the VIKTOR side of things in the file.get_value() method or if I simply need to put the creation of my GEFFile object in a try statement and handle any UnicodeEncodeErrors myself?
Unfortunately practice is often different from the theoretical norm. GEFs should only be encoded with basic ASCI or extended ascii (ISO-8859-1 or windows-1252). But in this case the GEF is probably encoded with utf-8.
But multiple things went wrong with this GEF, i think (I have to check the GEF itself to verify my suspicion)
You can notice this because the ö is encoded with 2 bytes 0xC3 0xB6, this is typical for utf-8. But opening the file with ISO-8859-1: 0xC3 → Ã and `0xB → ¶.
But the error is raised because some character is encoded (in utf-8) with 0x83 byte, but in 'ISO-8859-1, the 0x83 byte is not used. So in that case you get an encoding error.
This is either caused by a different character (maybe σ character? ) or the above characters got solidified in utf-8 somehow (be decoding the file using `iso-8859-1 and encoding/saving it using utf-8).
tl;dr:
The source file is encoded using ‘utf-8’ and if you opened it in text-mode, you should specify ‘utf-8’
Thanks for the fast reply. In most cases ISO-8859-1 works perfectly. Therefore, I think that if I change the encoding to utf-8 it might work for the gef in my case but it might cause other gefs to raise an error upon uploading. What would you recommend me to do to make sure the code is as robust as possible?
I am thinking about using a try statement to try to decode using ISO-8859-1 and if this fails try to decode it with utf-8. I am however not sure if this is an appropriate solution.
The case that ISO-8859-1 works normally is that for non-special characters, the bytes are identical for all major encodings (ISO-8859-1, windows-1252 and utf-8). Only when special characters get involved, the encodings might cause problems.