Hi all,
Inspired by the post made by @kvangiessen for last week’s Snippet Wednesday, I decided to share a snippet this week on a case where I had to speed up calculations dramatically to make an app worthwhile. In short, I achieved this by running the calculations in parallel.
The Snippet
Let’s say you have an analysis or calculation that you would like to run. As example I will use a simple calculation that includes some equation, and a sleep function to simulate the delay that one would typically have with a long duration calculation:
Blocking method
import random
import time
def blocking_method(name: str, x: float, y: float):
sleep_time = random.randrange(1, 5)
print(f"Starting analysis {name}, sleeping for {sleep_time}\n")
time.sleep(sleep_time)
z = x ** 2 + y ** 2
print(f"Completed analysis {name} \n")
return z
If you were to run a 100 or so of these calculations, that would take quite some time to complete. This can be shortened dramatically by running all of these in parallel. Running all cases in parallel is usually not feasible due to constraints such as computational resources or number of licenses (in the case of calculating with licensed third party software). Therefore, you need to batch the scenarios or cases to a number that fits the constraints. Here is the snippet for running the cases in batches:
Batch run method
from typing import List, Tuple
import asyncio
from concurrent.futures import ThreadPoolExecutor
async def non_blocking_batch_run(models_input: List[dict]) -> Tuple[dict]:
"""
:param models_input: [{"name": <name>, "x": <x>, "y": <y>}, ...]
"""
loop = asyncio.get_running_loop()
# define the maximum number of operations possible per batch
with ThreadPoolExecutor(max_workers=3) as pool:
# The method `blocking_method` runs in parallel within this asynchronous method.
results = await asyncio.gather(*[loop.run_in_executor(pool, blocking_method, *run.values()) for run in models_input])
return results
In the case where you are limited by licenses, you could simply define your max_workers to the number of licenses available. In the case where you are limited by computation resources, you will have to test with the number of parallel running cases, increasing the cases until you reach the limit of the resources. Make sure to use representative cases when doing these tests.
Take note: the snippet converts a dictionary to positional arguments. This assumes that the dictionary is ordered.
To round off all of this, the concurrent code needs to be run using the asyncio.run function. Here is a snippet that shows example input with the run function:
Test batch method
test_models_input = [
{'name': 'Case 1', 'x': 1, 'y': 1},
{'name': 'Case 2', 'x': 2, 'y': 1},
{'name': 'Case 3', 'x': 1, 'y': 3},
]
test_results = asyncio.run(non_blocking_batch_run(test_models_input))
Results
Running the example provided above, I get the following results:
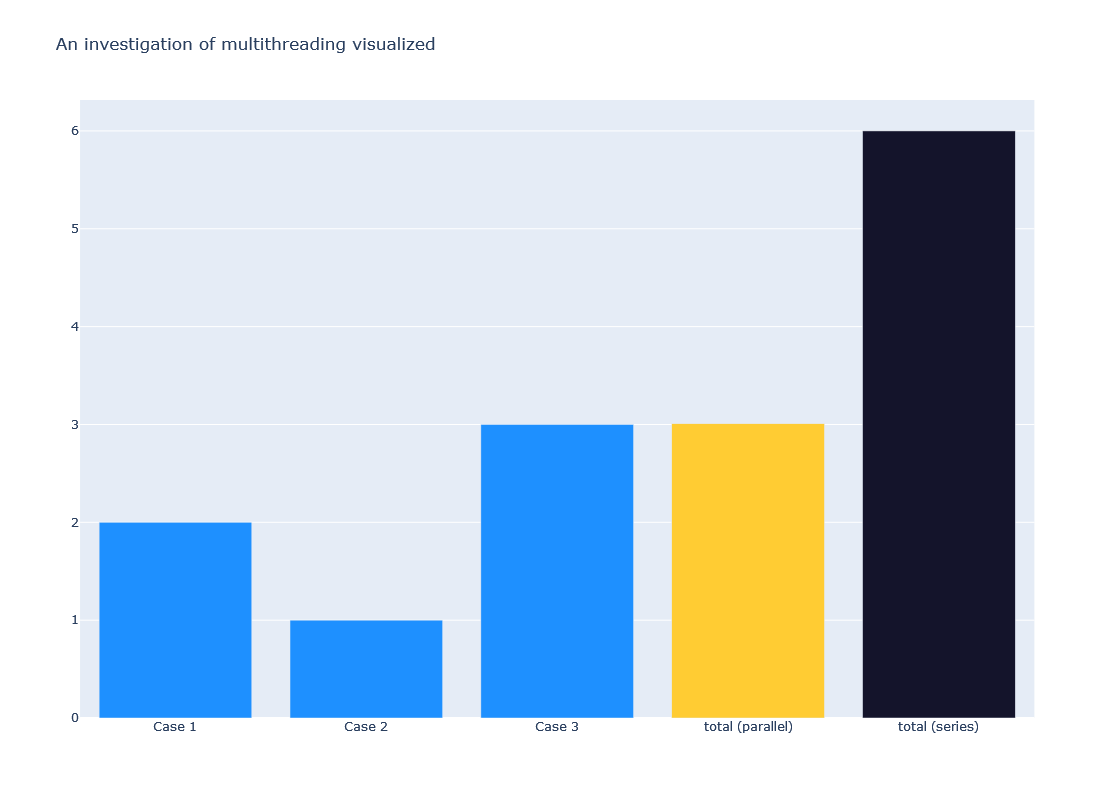
The results generated above was based on three cases run in batch where the maximum number of workers was 3. This allowed for all three cases to be run in parallel.
Above’s example shows that the time it takes to run the slowest calculation is almost equal to the batch run. That is quite exciting, as this provides many opportunities for developers to improve their applications!
Project Description
Sometimes community members are curious on what type of projects we applied these snippets. Here I’ll give a short description of the project I had to optimize:
The project was an extension on a development where sheetpiles could be designed parametrically, by also using integrated third party software. This was already valuable for the engineers, but they wanted to take the next step: optimizing sheetpile designs. For this they wanted to calculate many possible sheetpile designs, and based on the results, find a suitable optimal solution. The big problem was that it took quite some time to do such an optimization. But what if one were able to run many different scenarios parallel with one another? Well, with this, I introduced this Snippet Wednesday snippet to the project!
There have been other projects that also applied this concept, although it may have differed, depending on the Python version and project requirements. It would be great to see some other examples of projects posted in this topic’s chat.
Credits and Sources
This is a snippet that was initiated back in the Jurassic era ![]() by my colleague @rdejonge (just joking, it was only 4 years ago). Therefore, credit where credit’s due.
by my colleague @rdejonge (just joking, it was only 4 years ago). Therefore, credit where credit’s due.
Also, this snippet by no means explains the technicalities of multithreading. This was also not the intention, as I merely wanted to convey the concept in a way that can be applied in little time. I hope I have done that in good manner. For those that are interested a deeper dive🤿, here are some links (although a simple Google search would give you good results as well):